Algorithms
-
Exact or approximate (aka fuzzy)
-
Online or offline
- Online algorithms search without pre-processing the target data, and need to traverse all data during the search
- Offline algorithms pre-process the target data and may store it in memory or on disk to speed up query processing (aka indexeing)
-
Exhaustive or heuristic
- Exhaustive algorithms guarantee to find all occurrences of the query in the target
- Heuristic algorithms may not find all similar data. In heuristics, a reduction of the search time is achieved by evaluating only the statistically interesting patterns
-
Depends on the size of the alphabet and length of strings
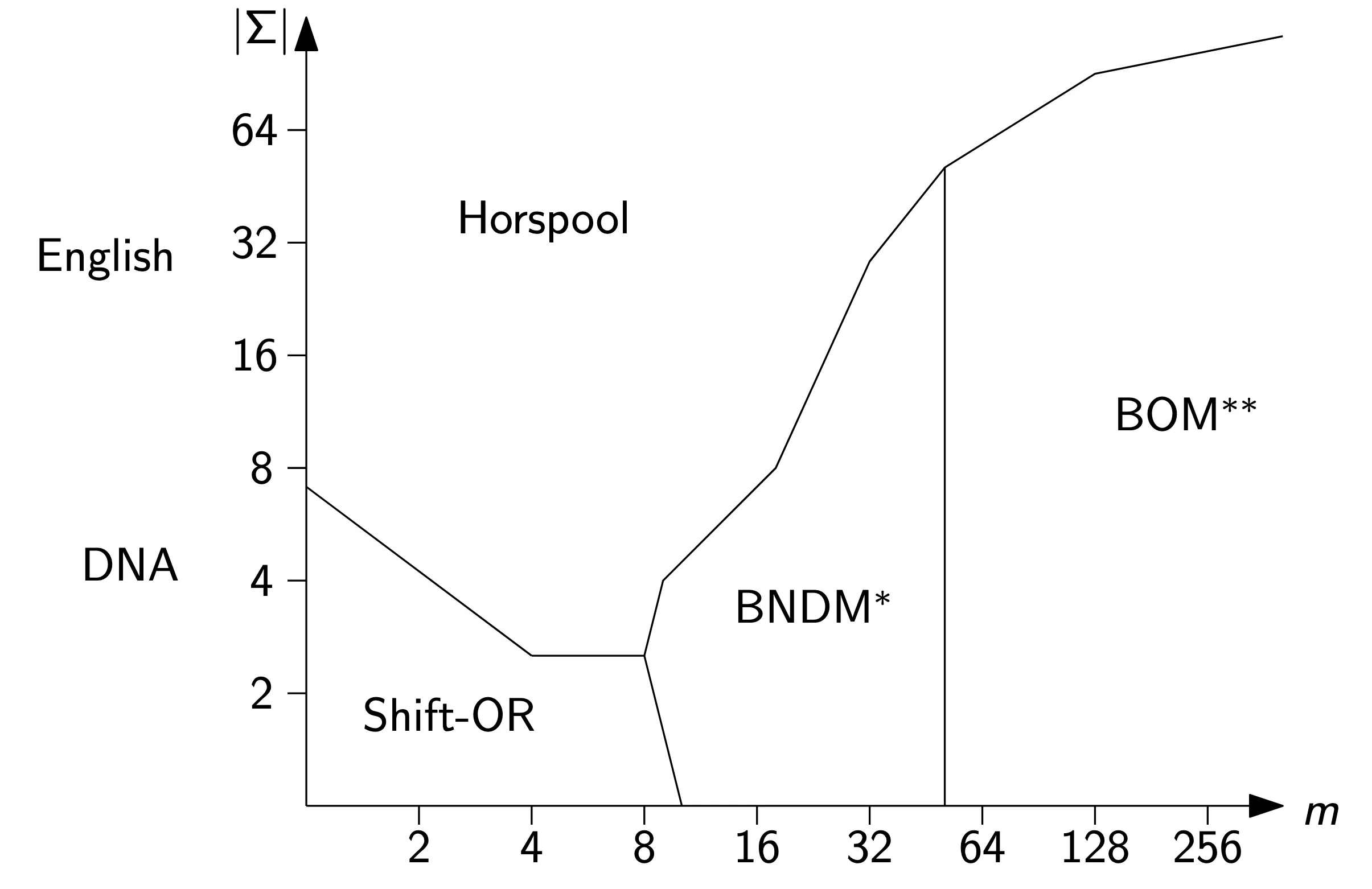
Source: Gonzalo Navarro & Mathieu Raffinot, 2002
-
Algorithms differ by computational and space complexity
Reading
| Approximate | online |
| offline | |
| Exact | online |
| offline (missing) |
Approximate online
Approximate offline
We can broadly classify them into three categories.
Gram-based method. They transform strings into grams and develop a filtering condition: if two strings are similar then they must share a certain number of common grams. To enhance the performance, they also proposed prefix-filtering based technique: they generated a prefix for each string by selecting some of its representative grams and deduced that if two strings are similar, their prefixes must share a common gram. They developed effective pruning techniques to generate high-quality prefixes.
- C. Li, J. Lu, and Y. Lu. Efficient merging and filtering algorithms for approximate string searches. In ICDE, pages 257–266, 2008.
- C. Xiao, W. Wang, X. Lin, and J. X. Yu. Efficient similarity joins for near duplicate detection. In WWW, pages 131–140, 2008.
- C. Xiao, W. Wang, and X. Lin. Ed-join: an efficient algorithm for similarity joins with edit distance constraints. PVLDB, 1(1):933–944, 2008.
- J. Wang, G. Li, and J. Feng. Can we beat the prefix filtering?: an adaptive framework for similarity join and search. In SIGMOD Conference, pages 85–96, 2012.
Trie-based method. They build a trie structure on top of strings and utilized the trie structure to do effective pruning: if two strings are similar, their prefixes must be similar enough. Different from gram-based method, these methods can directly find all answers and do not employ a filter-and-verification framework.
- S. Ji, G. Li, C. Li, and J. Feng. Efficient interactive fuzzy keyword search. In WWW, pages 433–439, 2009
- G. Li, S. Ji, C. Li, and J. Feng. Efficient type-ahead search on relational data: a tastier approach. In SIGMOD Conference, pages 695–706, 2009.
- G. Li, S. Ji, C. Li, and J. Feng. Efficient fuzzy full-text type-ahead search. VLDB J., 20(4):617–640, 2011.
- J. Wang, G. Li, and J. Feng. Trie-join: Efficient trie-based string similarity joins with edit-distance constraints. PVLDB, 3(1):1219–1230, 2010.
- J. Feng, J. Wang, and G. Li. Trie-join: a trie-based method for efficient string similarity joins. VLDB J., 21(4):437–461, 2012.
Partition-based method. They partitioned strings into segments and proved that if two strings are similar then they must share some common segments. They utilized this property to support similarity join and search.
- W. Wang, C. Xiao, X. Lin, and C. Zhang. Efficient approximate entity extraction with edit distance constraints. In SIGMOD Conference, pages 759–770, 2009.
- J. Wang, G. Li, and J. Feng. Fast-join: An efficient method for fuzzy token matching based string similarity join. In ICDE, pages 458–469, 2011.
- G. Li, D. Deng, J. Wang, and J. Feng. Pass-join: A partition-based method for similarity joins. PVLDB, 5(3):253–264, 2011.
-
String Similarity Joins: An Experimental Evaluation ↗
-
EmbedJoin: Eicient Edit Similarity Joins via Embeddings ↗
GramCountLuis Gravano, Panagiotis G. Ipeirotis, H. V. Jagadish, Nick Koudas, S. Muthukrishnan, and Divesh Srivastava. 2001. Approximate String Joins in a Database (Almost) for Free. In VLDB. 491–500. ↗AllPairRoberto J. Bayardo, Yiming Ma, and Ramakrishnan Srikant. 2007. Scaling up all pairs similarity search. In WWW. 131–140. ↗FastSSThomas Bocek, Ela Hunt, Burkhard Stiller, and Fabio Hecht. 2007. Fast similarity search in large dictionaries. University ↗ListMergerChen Li, Jiaheng Lu, and Yiming Lu. 2008. Efficient Merging and Filtering Algorithms for Approximate String Searches. In ICDE. 257–266. ↗EDJoinChuan Xiao, Wei Wang, and Xuemin Lin. 2008. Ed-Join: an efficient algorithm for similarity joins with edit distance constraints. PVLDB 1, 1 (2008), 933–944. ↗QChunkJianbin Qin, Wei Wang, Yifei Lu, Chuan Xiao, and Xuemin Lin. 2011. Efficient exact edit similarity query processing with the asymmetric signature scheme. In SIGMOD. 1033–1044. ↗VChunkWei Wang, Jianbin Qin, Chuan Xiao, Xuemin Lin, and Heng Tao Shen. 2013. VChunkJoin: An Efficient Algorithm for Edit Similarity Joins. IEEE Trans. Knowl. Data Eng. 25, 8 (2013), 1916–1929. ↗PassJoinGuoliang Li, Dong Deng, Jiannan Wang, and Jianhua Feng. 2011. PASS-JOIN: A Partition-based Method for Similarity Joins. PVLDB 5, 3 (2011), 253–264. ↗AdaptJoinJiannan Wang, Guoliang Li, and Jianhua Feng. 2012. Can we beat the prefix fltering?: an adaptive framework for similarity join and search. In SIGMOD. 85–96. ↗
-
Top-k String Similarity Search with Edit-Distance Constraints ↗
-
MinJoin: Efficient Edit Similarity Joins via Local Hash Minima ↗
Exact online
- Chronology of Exact Online String Matching Algorithms ↗
- Exact string matching algorithms ↗
- The String Matching Algorithms Research Tool ↗
- The Exact Online String Matching Problem:a Review of the Most Recent Results ↗
- Exact String Matching Algorithms: Survey, Issues, and Future Research Directions ↗
- Technology Beats Algorithms (in Exact String Matching) ↗